Working in multidimensional spaces is not just for science fiction writers.
One important part of machine learning, data mining, pattern recognition, and knowledge discovery is transforming data of interest–images, texts, genomes, computer network packets, etc.–into multidimensional spaces for further analysis. In these spaces, sometimes composed of many thousands of dimensions, we can then perform supervised and unsupervised learning.
But humans–the users of these machine learning algorithms–have difficulty in seeing/thinking beyond just three dimensions, so if you want humans involved in machine learning systems, you need to think about effective ways of transforming the data back into low-dimensional spaces for human consumption.
While the main of my PhD dissertation, “Knowledge Discovery in Computer Network Data: A Security Perspective,” was focused on the “Denoise” box in the figure below, where most of the machine learning takes place, one important element of my system was the “Interact” box.
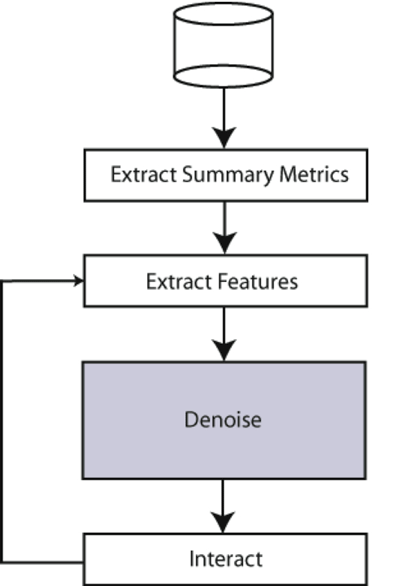
Unlike most machine learning algorithms, which simply “give” the answer to the human user, my system put the user in the middle of the algorithm, letting the user interact with and modify the direction of analysis. I chose to represent the data in just two dimensions for the user.
As an example, here is a dataset of Science News documents, which live in a 32130-dimensional space, transformed into two dimensions.
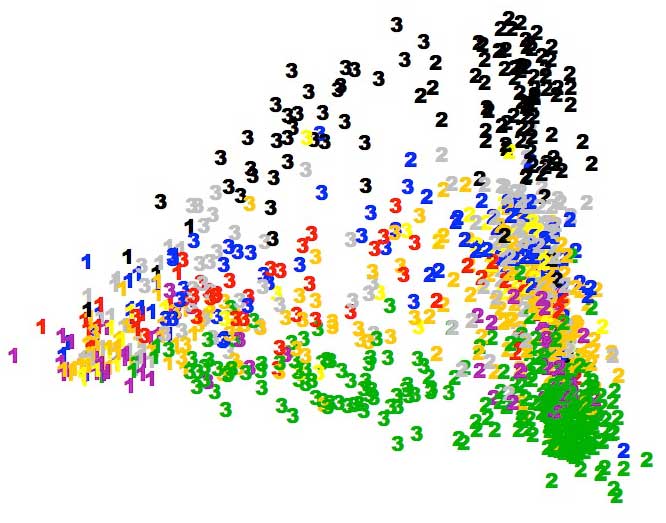
In the image you can see many colored numbers. Each number represents one Science News document, and the color of the number represents the “type” of Science News article–Astronomy (black), Medicine (green), Physics (blue), etc.
Note that my transformation of the articles into two dimensions is not arbitrary–I transformed them in such a way as to maximize document similarities. In other words, two medicine articles should appear closer together than a medicine article and an astronomy article.
Thus, this transformation helps cluster articles together. This is useful in cases where you don’t know the types of articles beforehand–you can group similar articles together without even having read the articles.
My algorithm aids human-computer interaction by allowing the user to interact with the data through visualization and by “drilling down” into document clusters, which is useful when you are dealing with large datasets.
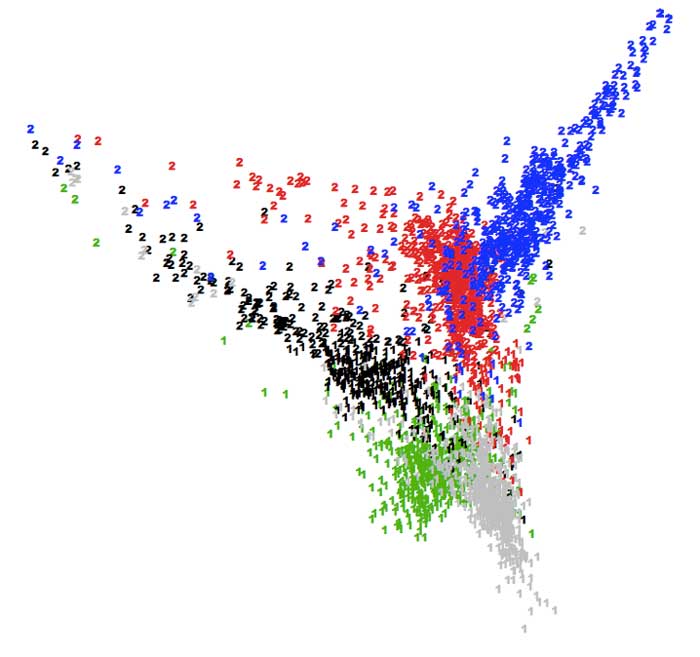
As another example, here is a projection of a large set of newsgroup documents into two dimensions, colored by newsgroup label: green = rec.autos, black = talk.politics.misc, red = soc.religion.christian, gray = comp.graphics, and blue = alt.athiesism.
For more information, please see:
- "Knowledge Discovery in Computer Network Data: A Security Perspective," Kendall Giles, Ph.D. Dissertation, Johns Hopkins University, Baltimore, Maryland, October 2006.